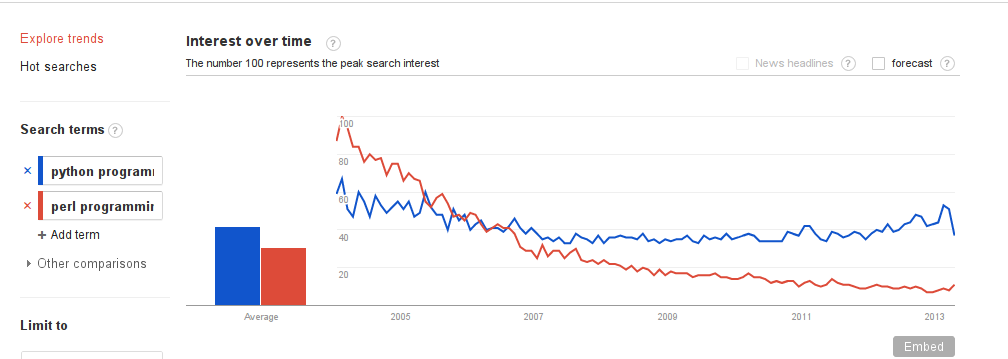
The sequester is hitting science funding in the US pretty hard. Francis Collins, the director of the NIH, is lobbying any way he can to get the NIH off the hook. In 2013, there will be 700 fewer grants awarded than in 2012. 4.7% cuts across the board to grant renewals.
So, here’s the Sequester Blues, sung by Dr. Collins himself. I like the guitar neck. We may all have to sing for our supper soon…
“Our aim here is to maximize amusement, rather than coherence.”
SCIgen developers
Joke papers have been known to sneak into otherwise serious publications. Notably, in the Sokal Affair, Alan Sokal, a physicist, published a nonsense paper in Social Text, a leading journal in cultural studies. After it was published, Sokal revealed this paper to be a parody, kicking off a culture war between the editors of Social Text who claimed they accepted the paper on Sokal’s authority, and Sokal & others who said that this was exactly the problem: papers should be subject to review, rather than being accepted on authority. The Sokal affair highlighted the cultural differences between certain sections of the social sciences and the natural sciences, specifically about how academic merit should be established.
Another well-publicized hoax publication occurred when a group of MIT students wrote SciGEN, a program that generates random computer-science papers. One such paper was accepted to the WMSCI conference in 2005, in a “non peer-reviewed” track. Once the organizers learned they’ve been had, they disinvited the “authors”, which did not stop them from going to the conference venue anyway, and holding their own session at the conference hotel.
Following the SCIGen incident, Predrag Radivojac and his team at Indiana University, Bloomington have developed a method to distinguish between authentic and inauthentic scientific papers, which he published as a (hopefully) authentic paper (PDF) in SIAM. The idea is to distinguish between true papers, and robo-papers such as those generated by SCIGen. Their method does the following: first, they pulled a set of about 1,000 authentic papers. Then they generated 1,000 papers from SCIGen. They then subjected both types of papers to Lempel-Ziv compression, similar the kind you use to zip your files. Why use compression? The ratio of sizes between compressed and uncompressed documents is a good way to measure the information that document contains. Since compression algorithms rely on the frequency of character patterns in the document, one may assume that documents with different patterns can be characterized by different compression ratios. The team from IU exploited the differences between typical patterns in robo-papers and those in real papers, and created a method that can distinguish between the types of papers based on their compression profiles. The method is available online. This can help reduce the number of robo-papers from going into robo-conferences.
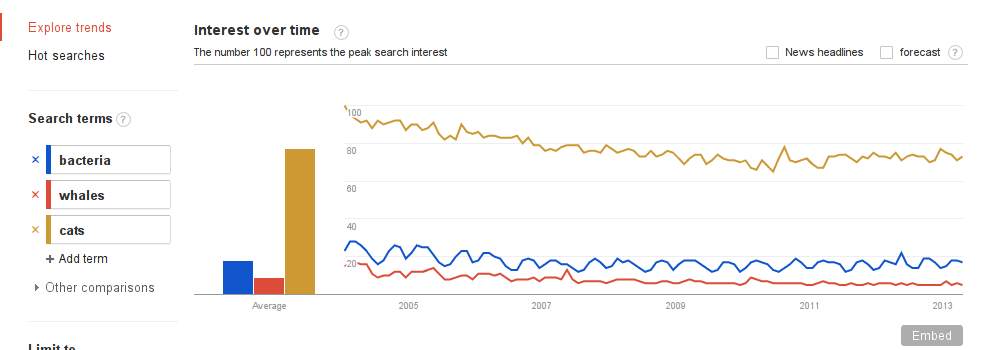
We like to think of ourselves as the better results of evolution. We humans are particularly proud of our ability to communicate, having invented cell phones, the Internet, and extended forelimb digits as sophisticated means of communication not found anywhere else in nature.
Not true. Where there is life, there is communication. Vocal, visual, chemical. Some fish even communicate electrically. Take, that, Alex G. Bell! From bacteria to Blue Whales, from yeast to yak, everyone communicates. Including plants.
When some plants are attacked by sap-sucking aphids, they emit volatile compounds into the air. These volatiles serve as a defense mechanism, and in more ways than one. First, they serve to repel the aphids attacking the plant. Second, they attract the aphids natural enemies, wasps. But there’s more to that: a team from the University of Aberdeen and the James Hutton Institute show that some plants use fungi to communicate the presence of aphids, allowing those plants to emit wasp-attracting and and aphid-repelling volatiles even before they have been physically attacked.
Pea Aphids. Source: PLoS Biology, 2/2010. Credit: Shipher Wu (photograph) and Gee-way Lin. National Taiwan University.
Introducing the arbuscular mycorrhyza (AM) fungus, which has been living symbiotically with plants for at least 460 million years. The AM fungi and their symbiotic plants create mycorrhiza, structures in which the fungus penetrates the plant’s root cells forming arbuscules, branched structures interfacing within the plant cells. The arbuscules allow the exchange of nutrients between plant and fungus. The result allows plants to capture nutrients such as phosphate, zinc and nitrogen. AM fungi are found in 80% of vascular plant families (plants which transport nutrients and water via a vascular system), which makes them an essential part of plant life. While we think of fungi mostly as mushrooms, those are only the fruiting bodies of the fungi. Like all fungi, the major biomass of AM lies in the mycelium: a network long, thin filamentous structures that branch within the soil where they grow. The hypothesis that the researchers tested was: are the AM fungus mycelia used to communicate information between plants, in a sort of symbiotic nervous system?
Flax root cortical cells containing paired arbuscules. Credit: MS Turmel, University of Manitoba. Source: wikipedia
To answer this question, they planted bean seedlings in a pot whose soil contains an AM fungus. They isolated some seedlings from the AM fungus using a fine mesh, while others had only their roots isolated, or were not isolated at all. All plants were covered individually with bags to ensure they do not communicate via the air using volatiles. Then the researchers infested one plant with aphids, and collected the volatiles from the other plants. They discovered that the plants connected by the fungal network produced volatiles that repelled aphids and attracted wasps. Those plants which had no hyphal contact produced much less of these volatiles. In the control, the plants in the fine mesh that had hyphal contact only, but no root contact, also produced anti-aphid volatiles.
Bottom line: plants can communicate via fungal networks, although we don’t quite know how yet. Also, probably this is not an exclusive mode of communication. Apparently, symbiosis is not just about food or protection from predators or the elements. It’s also about conveying information. Very cool. Zdenka Babikova, Lucy Gilbert, Toby J. A. Bruce, Michael Birkett, John C. Caulfield, Christine Woodcock, John A. Pickett, & David Johnson (2013). Underground signals carried through common mycelial networks warn neighbouring plants of aphid attack Ecology Letters, 16 (7), 835-843 DOI: 10.1111/ele.12115
Our main problem is turning these DNA data into useful information. Finding genes and other functional genomic element, characterizing them, understanding their function and their impact on Life – all these are challenges that will remain with us for a long time, and which have revolutionized biology into the information science it is today.
Before all that, science is a collaborative endeavor. To collaborate, scientists need to exchange data, including sequence data. But when the the flood of data is very hard to channel into the narrow Internet tubes.
We need to compress these data. There are generic compression software – zip, gzip and bzip2 come to mind. However, could we do better with a solution tailored to DNA? After all, we are talking about a string taken from a four-letter alphabet, with many repeats made.
So the Pistoia Alliance announced a $15,000 prize for “putting forward a prize fund of US$15,000 to the best novel open-source NGS compression algorithm submitted before the closing date of 15 March 2012.” The paper describing the competition recently came out in GigaScience. (Which is why I am hearing about this only now).
The nice thing about Sequence Squeeze is that the scoreboard was dynamic and gave immediate feedback to how well a compression algorithm was doing. The criteria for performance were a combination of time, CPU usage, memory usage, compression ratio, and decompression quality. To wit:
Each judging instance contained a simple script which controlled the judging process. It operated as follows:
1. Download the entry
2. Set up a the contest data (a random extract from the 1000 Genomes Project)
3. Secure the firewall
4. Run the entry in compression mode
5. Measure CPU and memory usage
6. Assess the compression ratio
7. Run the entry in decompression mode
8. Check that the total combined output files contain exactly the same information (header, sequence, and quality lines) as the input files
9. Update the results database
10. Email the results
The winner of the first (and, as far as I can tell, the only) round of Sequence Squeeze was James Bonfield from the Sanger Institute. You can read more about Sequence Squeeze in the Pistoia Alliance’s blog and in the paper.
Holland RC, & Lynch N (2013). Sequence squeeze: an open contest for sequence compression. GigaScience, 2 (1) PMID: 23596984
Cancer and microbiology have been closely linked for over 100 years. Cancer patients are usually immunosuppressed due to chemotherapy, requiring special treatment and conditions to prevent bacterial infection. Bladder cancer is typically treated with inactivated tuberculosis bacteria to induce an inflammatory response which turns against remaining cancer cells, with remarkably effective results. Also, viruses are known to cause cancer, including papillomavirus (cervical cancer), Hepatitis B (liver cancer), and HTLV (human T-lymphocyte virus, causing lymphoma). In 1982, the bacterium Helicobacter pyloriwas discovered to be the main cause of gastric ulcers, and the first direct link between bacteria and cancer — stomach cancer — was established. The link between chronic ulcers and stomach cancer was already well known: what was not knows is that bacteria were the initial cause of stomach ulcers. Since then, several other suspects have been named, including links between Chlamydia and lung cancer, and Salmonella and gallbladder cancer.
Should DNA be subject to copyright law, rather than patent law?
Section 101 of Title 35 U.S.C. sets out the subject matter that can be patented:
Whoever invents or discovers any new and useful process, machine, manufacture, or composition of matter, or any new and useful improvement thereof, may obtain a patent therefor, subject to the conditions and requirements of this title.
Today SCOTUS ruled that naturally occurring genes cannot be patented [PDF]. The ruling was made in the lawsuit against Myriad Genetics and their patent on BRCA1/2. The decision comes on the heels of Angelina Jolie’s decision to have a preventative double mastectomy, when she discovered she had a BRCA1 mutation that gave her an 87% chance of developing breast cancer before the age of 90. The decision was hailed as beneficial to patients and healthcare, and will help reduce the costs of genetic tests and cancer screening, removing the monopoly that human gene patents have granted.
In a nutshell SCOTUS’s decision is elegantly summarized here (all quotes from now on are from the above ruling):
Finding the location of the BRCA1 and BRCA2 genes does not render the genes patent eligible “new . . . composition[s] of matter,”
A new paper from my lab and Patsy Babbitt’s lab in UCSF has recently been published in PLoS Computational Biology. It is something of a cautionary tale for quantitative biologists, especially bioinformaticians and system biologists.
Genomics has ushered biology into the data rich sciences. Bioinformatics, developing alongside genomics, provided the tools necessary to decipher genomic data. But genomic data provides us with the instruction book: what the organism is capable of doing. To see what the organism actually does we need to run experiments to interrogate the biological pathways that together constitute life. But biochemical experiments only tell you about a few proteins at a time. Slowly. Much slower than the information gain from genomics.
A lab can spend decades deciphering a single biological pathway. A professor can spend her entire career investigating how a handful of proteins interact with each other and affect a certain cellular process. But in the age of genomics and systems biology this seems so dated; if we can sequence a human genome for $5,000 and take only a couple of days to do so, we would also like to analyze cellular pathways with the same ease. The rate by which we gain knowledge in genomics is much faster than that in molecular biology and biochemistry. And that can be frustrating.
Great bit of research showing the amazing adaptation of bat tongues to nectar feeding.
Harper, C., Swartz, S., & Brainerd, E. (2013). Specialized bat tongue is a hemodynamic nectar mop Proceedings of the National Academy of Sciences DOI: 10.1073/pnas.1222726110
A lightning talk or a flash talk is a short presentation, typically anywhere between 1 and 5 minutes. They have been around for over 10 years in programmers’ meetings, and are slowly making inroads into scientific meetings.
The Good: lightning talks give more speakers a chance to present their material to an engaged audience; they cultivate succinct speaking skills. If you don’t like a talk in the session, you don’t have to wait for half an hour for the next one, you only have to wait for five minutes.
The Bad: a long session crammed with lightning talks may cause a jumble in the typical audience member’s brain. Talks that are early or late in the session may receive more attention due to the serial position effect, so that the middle talks are completely lost in the muddle, and the first and last couple of talks are those that are remembered.
Still, suppose you submitted an abstract to a conference, and made the cut for a lightning talk; what now?
Forget most of the skills you were taught for a regular 20 minute conference presentation, or 40 minute seminar. Lightning is a different beast. In a long talk, you teach a bit (background to the field & introduction to the problem at hand), show your stuff (your work), and advertise (show how your work contributed to the field, and how you left it better).
In a lightning talk, you want to get a single message across. And you want it to stand out. So you cannot afford to be too complex, you just don’t have the time.
Do: Prepare five to ten slides. Make sure they are sparse. An image or two per slide. No complex graphs. If you need words, write them big and few.
Do introduce yourself clearly at the beginning (name, affiliation, position, what you do)
Do clearly introduce whatever you are presenting.
Do give the acknowledgement slide at the beginning Although that is common practice in regular talk to give it at the end, in a lightning talk you want your last slide to be something else. See below.
Do speak at your normal pace.
Do make the last slide the impressive one: clear, strong message that will linger a minute longer during Q&A time, impressing itself upon the audience before it is time to move to the next talk. You do not want the acknowledgement slide to be last, as is traditionally done in longer talks.
Do: rehearse, rehearse, rehearse. Even if you are an accomplished speaker who can do a long talk without rehearsals, the lightning talk is a different beast. Waffling costs precious seconds, Moreover, getting back on track you may be tempted to speak faster to make up for lost time. Which is a no.
Don’t cram too many slides or be tempted to speak too fast. Find a way to convey your message at a normal speaking pace. Compressing more words into less time does not increase the information you convey, it actually deceases it. People can only process so much at a given time. Remember that a talk, including a lightning talk is about making people understand something new, not about you maximizing words-per-minute.
Don’t go over the allotted time. If you are not finished by the time the clock buzzes or the session chair signals you to get off, just say “sorry, time’s up. Catch me at the coffee break if you want to hear more.” — and step off the podium .
Patricia Babbitt, University of California, San Francisco. Protein similarity networks: Identification of functional trends from the context of sequence similarity
Alex Bateman, European Bioinformatics Institute Using protein domains and families for functional prediction
Anna Tramontano, “La Sapienza” University, Rome. TBA
Key dates:
April 20, 2013: Deadline for submitting extended abstracts posters & talks
May 9, 2013: Notifications for accepted abstracts e-mailed to corresponding authors
May 16, 2013: Deadline for presenters to confirm acceptance of invitation to speak.
July 20, 2013: AFP SIG preceding ISMB/ECCB 2013, Berlin.
Sequence and structure genomics have generated a wealth of data, but extracting meaningful information from genomic information is becoming an increasingly difficult challenge. Both the number and the diversity of discovered sequences are increasing, and the fraction of genes whose function is known is decreasing. In addition, there is a need for annotation which is standardized so that it could be incorporated into function annotation on a large scale. Finally, there is a need to assess the quality of the available function predictionsoftware.
For these reasons and many more, automated protein function prediction is rapidly gaining interest among computational biologists in academia and industry.
The Automated Function Prediction Special Interest Group (AFP SIG) has been part of ISMB since 2005. We call upon all researchers involved in gene and protein functionprediction and annotation, both computational and experimental, to submit an abstract to the AFP meeting. Authors of select abstracts will be invited to give a talk and/or present a poster.
We will also be discussing the upcoming second Critical Assessment of Function Annotations, or CAFA 2. CAFA 1 was a highly successful experiment, engaging 30 groups worldwide, and has resulted in 16 peer-reviewed papers in Nature Methods and BMC Bioinformatics.
We are looking forward to a new and expanded CAFA 2 in 2013-2014, which will include a cellular component prediction track, and a human-specific track.
I am not inclined to write polemic posts. I generally like to leave that to others, while I take the admittedly easier route of waxing positive over various bits of cool science I find or hear about, and yes, occasionally do myself.
But WSJ editorial from E.O. Wilson has irked me so much, I have decided to go for it. The upset I felt when reading this was on several levels: as a teacher, and a scientist, and as a person concerned for the future of science, and science literacy. In this editorial, Wilson promotes a type of scientific illiteracy that is dangerous if taken to heart by aspiring scientists.
In essence, Wilson draws from his personal experience as a successful scientist who is not only semi-illiterate in math, but proud of it. He claims that, if he succeeded as a math illiterate, so can other scientists, except in “a few disciplines, such as particle physics, astrophysics and information theory.” (All quotes are from said article, unless noted otherwise.) He claims that “Far more important throughout the rest of science is the ability to form concepts, during which the researcher conjures images and processes by intuition.” He continues to state that: ” The annals of theoretical biology are clogged with mathematical models that either can be safely ignored or, when tested, fail. Possibly no more than 10% have any lasting value.”