
On Joke Papers, Hoaxes, and Pirates
“Our aim here is to maximize amusement, rather than coherence.”
SCIgen developers
Joke papers have been known to sneak into otherwise serious publications. Notably, in the Sokal Affair, Alan Sokal, a physicist, published a nonsense paper in Social Text, a leading journal in cultural studies. After it was published, Sokal revealed this paper to be a parody, kicking off a culture war between the editors of Social Text who claimed they accepted the paper on Sokal’s authority, and Sokal & others who said that this was exactly the problem: papers should be subject to review, rather than being accepted on authority. The Sokal affair highlighted the cultural differences between certain sections of the social sciences and the natural sciences, specifically about how academic merit should be established.
Another well-publicized hoax publication occurred when a group of MIT students wrote SciGEN, a program that generates random computer-science papers. One such paper was accepted to the WMSCI conference in 2005, in a “non peer-reviewed” track. Once the organizers learned they’ve been had, they disinvited the “authors”, which did not stop them from going to the conference venue anyway, and holding their own session at the conference hotel.
Following the SCIGen incident, Predrag Radivojac and his team at Indiana University, Bloomington have developed a method to distinguish between authentic and inauthentic scientific papers, which he published as a (hopefully) authentic paper (PDF) in SIAM. The idea is to distinguish between true papers, and robo-papers such as those generated by SCIGen. Their method does the following: first, they pulled a set of about 1,000 authentic papers. Then they generated 1,000 papers from SCIGen. They then subjected both types of papers to Lempel-Ziv compression, similar the kind you use to zip your files. Why use compression? The ratio of sizes between compressed and uncompressed documents is a good way to measure the information that document contains. Since compression algorithms rely on the frequency of character patterns in the document, one may assume that documents with different patterns can be characterized by different compression ratios. The team from IU exploited the differences between typical patterns in robo-papers and those in real papers, and created a method that can distinguish between the types of papers based on their compression profiles. The method is available online. This can help reduce the number of robo-papers from going into robo-conferences.
Why do such joke papers keep amusing us? There are several reasons I can think of. First, as academics, we are subject to the constant frustration of having the writeup of our hard labor rejected by journals. We spend years perfecting our work, and then along comes Reviewer #3 and trashes it! For no good reason either! (Well, no good reason we care to admit to, anyway.) So it is refreshing to see someone “sticking it to the man”, and getting a purposefully false (and funny) paper past the academic watchdogs. Second, the Sokal affair specifically appears to validate the opinions some scientists hold against postmodern critique of science, namely that a lot of what goes on there is empty words and a fundamental misunderstanding of science. One might say the Sokal paper was a behind-the-lines commando attack in the Science Wars. Finally, well, there is that thing as old as humanity of enjoying a good gag at someone else’s expense. A joke paper is the ultimate leg-pulling: Hey, look! the Emperor in the Ivory Tower has no clothes! (Damn, mixing cliched metaphors is so pathetic meta.)
Aside from the guerrilla hoax paper, there is also the obvious joke paper. The joke paper is usually published not to poke fun at the publication venue, but rather to highlight some methodological problem, employing reductio ad absurdum. The Dead Salmon Paper published in the (already funny name) Journal of Serendipitous and Unexpected Results is one such example. Here the authors have shown the danger of not employing multiple hypothesis correction when performing statistical analyses. Namely, if you don’t do your statistics right, even a dead fish can show significant neural impulses when shown pictures of people.
Luis Pedro Coelho pointed me to the following joke paper, published in 2011: “Determinants of Age in Europe: A Pooled Multilevel Nested Hierarchical Time-Series Cross-Sectional Model” by Uchen Bezimeni. This was published in 2011 in European Political Science. (A legitimate journal, as far as I can tell). If you speak Russian, the author’s name (“No such scientist”) is a dead giveaway that this is not exactly a serious paper. So is the non-existent World Academy for Government Progress “Uchen” is “affiliated” with. (I don’t speak Russian, so thanks to Michael Galeprin for pointing out the meaning of the “author’s” name). Because it took me a bit to get my hands on the PDF (paywalled), and because I don’t know Russian, I didn’t know at first whether this was a subversive paper sneaked in under the editor’s radar, or a joke where the author and editor colluded. It is, quite obviously, the latter though. From the paper:
“As is usual in economics, in case we find a discrepancy between the theories and reality, we will have to declare reality faulty and try to bring it in line with our theory. Fortunately, the rate of un-hypothesized findings in the social sciences rapidly approaches zero.“
The point of the paper can be succinctly summarized as “correlation does not imply causation”. namely, the author looks for causes of age (note well: age not aging), other than the obvious-by-definition, which is time. And as anyone who has employed R without a license knows, if you look hard enough for significant patterns, you will find them.
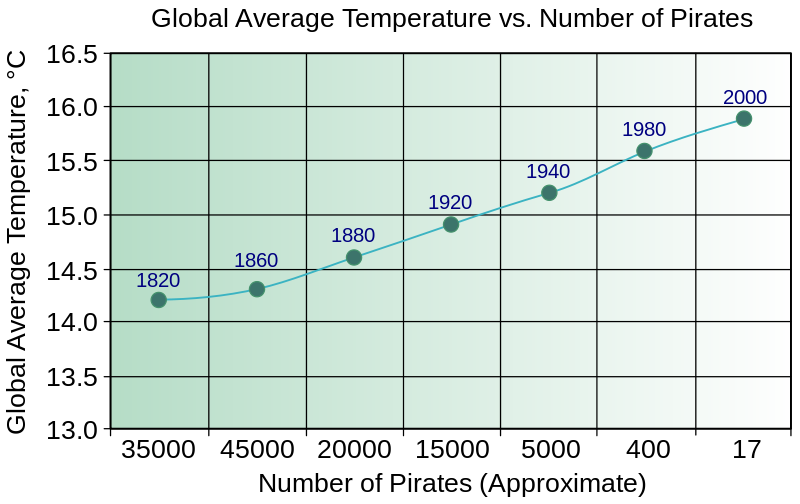
Decline in Number of Pirates Causes Global Warming. Source: wikipedia.
The author concludes that age is determined by all sorts of nonsense factors:
Our findings convincingly show that generalized trust in strangers, support for incumbent extremist political parties in provincial elections held in the month of January, and the percentage of overqualified women in the cafeterias of national parliaments are all statistically significant explanations of ‘age’.
Just like XKCD has shown a while ago:

A final note: when placing the Uchen Bezimeni joke paper through the inauthentic paper classifier at IU, it was classified as “inauthentic”. Obviously, this paper was written by a human (although it is not clear which human). But apparently the wording pattern is so different than that found in scientific papers, that the inauthentic paper classifier classified it as being written by a machine. Perhaps the classifier can be trained to distinguish between compression profiles for different types of papers? Let’s start with science vs. postmodernist papers. This will add some gasoline to the waning Science Wars fire….













Comments are closed.



