
Why scripting is not as simple as… scripting
If you haven’t read the transcript of Sean Eddy‘s recent talk “On High Throughput Sequencing for Neuroscience“, go ahead and read it. It’s full of many observations and insights into the relationships between computational and “wet” biology, and it is very well-written. I agree with many of his points, for example, that sequencing is not “Big Science”, and that people are overenamored with high throughput sequencing without understanding that it’s basically a tool. The talk, posted on his blog, prompted me to think, yet again, about the relationships between experimental and computational biology. A few things in this talk rubbed me the wrong way though, and this is my attempt to put down my thoughts regarding some of Eddy’s observations.
One of Eddy’s main thrusts is that biologists doing high throughput sequencing should do their own data analyses, and therefore should learn how to script.
The most important thing I want you to take away from this talk tonight is that writing scripts in Perl or Python is both essential and easy, like learning to pipette.
There are two levels to this argument, I actually disagree with both: first, scripting and pipetting are not the equivalent in the skill level they require, the training time, the aptitude, the experience required to do it well, and the amount of things that can be done wrong. It may very well be that scripting is a required lab skill in terms of needs in the lab, but it is not as easy to learn to do proficiently as pipetting. (Although pipetting correctly is not as trivial as it sounds.)
But there is a deeper issue here, bear with me. Obviously, different labs, and people in those labs, have different skill sets. After all, it would be surprising if the same lab to was proficient in two completely disparate techniques, say both high-resolution microscopy and structural bioinformatics. We expect that labs specialize in certain lines of research, the consequent usage and/or development of certain tools, and as a result the aggregation of people with a certain skill sets and competencies in that lab. There are excellent biologists who do wonders with the microscope in terms of getting the right images. Then there are others who have invaluable field skills, or animal handling, primary cell-culture harvesting and treatment, growing crystals, farming worms, and the list goes on. All of those require training, some require months of experience to do right, and even more years to do well. All are time consuming, both in training and in execution, and all produce data, including, if needed (and sometimes not-so-needed) large volumes data. Different people have different aptitudes, and if a lab lacks a certain set of skills to complete a project, it is not necessarily a deficiency. It may be something that can be filled through collaboration.
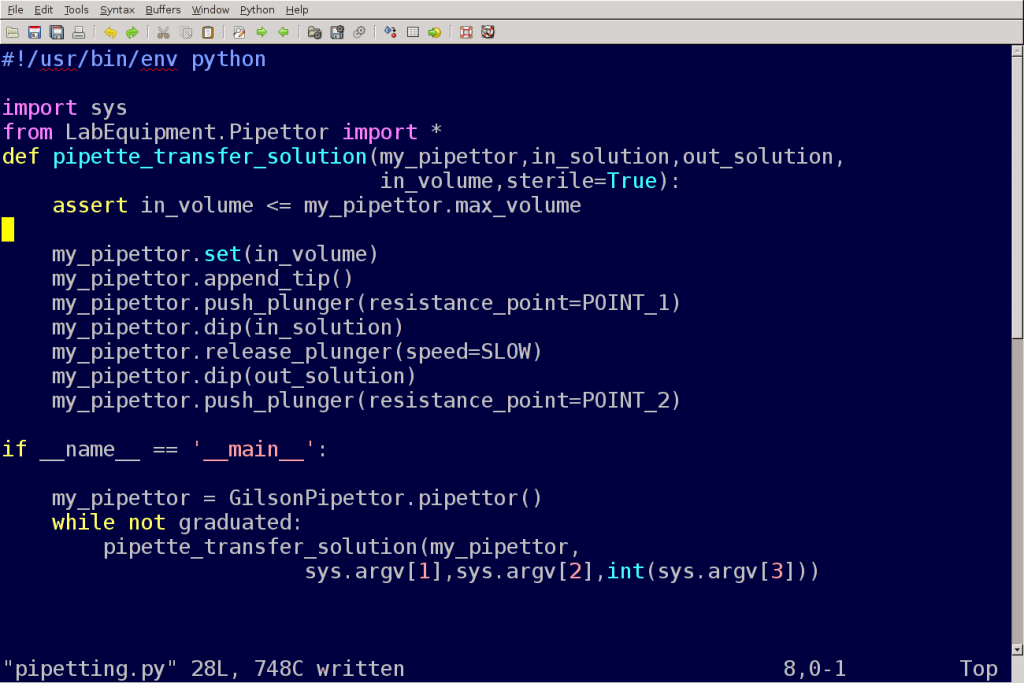
But ah, you say, those skills I listed are necessary for data collection, and yes, they are needed. But one is not a real scientist if one cannot perform proper data analysis, and one needs to know what is being asked to properly collect the data. Would an answer to a genomic interrogation be best given by a 10x coverage to a 100x? Transcriptome, exome or genome? How do you determine the value of the results? Is it via statistical significance? Strength? Do you require multi-hypothesis testing? Which statistical analyses would be used? How will the results be visualized meaningfully? Eddy is right, one cannot just collect data and expect the bioinformatics core to apply tools to it, any more than you run a Western and expect someone to use a ruler for you. And, as he says “To analyze data from a biological assay, you have to understand the question you’re asking, you have to understand the assay itself, and you have to have enough intuition to anticipate problems, recognize interesting anomalies, and design appropriate controls“. Also, Eddy talks mainly of high throughput data, which cannot be simply analyzed using a spreadsheet (not a good idea in most cases), or generic software (although more on that later). Eddy concludes that scripting skills are universally needed in experimental labs doing high throughput data collection, because one cannot anticipate what sort of data questions one would need answered, hence common software tools are usually not applicable. So he proposes that anyone dealing with these data should have the scripting skills, on top of the domain knowledge that includes not only data collection methods, but an intimate understanding and knowledge of the organism or biological system in question. That’s a tall order! Especially because high throughput sequence data that they would need considerable statistical and algorithmic knowledge. In his talk, Eddy asks his audience to implement a random sampling algorithm from pseudocode, and tells them it would not take them more than an hour. Frankly, I find that example rather ambitious, and almost self-defeating to Eddy’s argument that high-throughput biologists should be the Jills and Jacks of both data collection and analysis trades, and that scripting is easy as pipetting. I believe that he underestimates the volume and value of domain knowledge for biologists for which high throughout data generation is another tool in the box they have for understanding life. Furthermore, I believe he also underestimates the volume and value of analytical skills required. Scripting is an implementation: scripting is used to implement a knowledge of statistical analyses, basic algorithm implementation, knowledge of data formats (and converting between them… grrr…), data visualization and so on. Ther are whole boxcars of data analysis and data management skills needed, to which scripting is the engine. The train won’t move without the engine, but the engine alone is useless: why drive it if you are not hauling freight?
Moreover, Eddy says:
If biologists did their own computational data analysis experiments using scripts like pipettes, and bioinformaticists wrote robust pipelines and components for those analyses that biologists used like we use kits, then computational biology research groups like mine are in the business of enzyme engineering.
This division of labor is one with which I disagree. Not only do I not believe it is so neat, I don’t even think that the division is solely, or even majorly, along those lines. Eddy has left out at least one rather large class of scientists, those that use the vast amounts of data out there to explore new hypotheses about life and perhaps provide new answers. Those are the bioinformaticists who are well-versed in biology, but also have programming skills that go beyond scripting, into the realm of algorithm development and large scale data management. They harness these skills to collect, manage, and interrogate third party data, and they find new evolutionary relationships between genes and genomes, produce new insights about genetic and metabolic cellular systems. They look at metagenomic and metabonomic data and produce new insights on microbiomes and their ecological roles and functions. They analyze protein structure data and report on how these structure evolve, or fold, or interact with each other and with other molecules. They look at collections of genomes and hypothesize on evolutionary relationships, gene and genome evolution. They look at transcriptomic and proteomic data, and provide phenotype to genotype relationship. They rarely generate their own data, but use the masses of third-party data that are out there. The questions they ask and answer involve the knowledge and use of statistics, programming (far beyond scripting) and, through all of that, knowing the biological systems they are dealing with, and what is the biological meaning and impact of their analyses. For full disclosure, I consider my lab to be mostly in that research camp, in our own humble way. As an aside we also have good pipetting skills, although those are exclusively practiced by my students in the instructional labs that they teach, and by me during lunchtime when I sip my cold drink through a straw. (What? You’re not supposed to use your mouth for pippeting? Since when?)

Source: National Library of Medicine
My lab also develops some pipelines, and methods. We love methods, as every scientist should (although, not all love to develop or should be developing them): methods and discovery feed into each other. We also collaborate with biologists to help analyze their data, either through our own programming or novel applications of methods. One such collaboration we not only applied our programming skills (which took a few weeks of work), but also used our own domain knowledge in microbiology to unravel an apparent anomaly as to why supposedly pathogenic bacteria enriched in an infant’s gut by a diet of breastmilk are seemingly beneficial for the developing infant. I know of dozens of other labs like mine, drylabs that work on biological discoveries through scripting, programming (and everything in between), application of statistics, visualizations, pipeline integration, and through it all, the knowledge of biology.
I’m therefore not of the opinion, expressed from time to time, that bioinformatics will eventually become either one of scriptology for wetlabs, pipeline engineering by programmers for biologists, or algorithm development. Yes, these things are happening, but a lot more is happening too. The process of science is messier than these neat divisions, and there are many cross-interactions between methods, data, and biology than the above three options encompass. So shouldn’t biologists, especially those doing high-throughput data collection learn scripting? Of course they should! They should do that before they even set foot in a lab. Any science training should include some basic programming, along with statistics, calculus, and advanced algebra. Biology has ceased to be the “non-math” science for a long time. (As an aside, it’s been at least 25 years since my alma mater, the Hebrew University, has been mandating that all undergraduate science majors take these courses, and I am still surprised when I learn that not all universities require that). Does that mean they would be proficient in scripting? Not necessarily. Should they? That is dependent upon many variables, including the lab’s time and resources, and the basic proficiencies of its members. They may be able to do some scripting in house, some via usage of third party tools, and some by going to the “dryer” biologists out there.
Bottom line: scripting is not as simple as pipetting. Come to think of it, scripting is not even as simple as scripting.
A big thanks to Leighton Pritchard for important comments and insights.

















[…] Source: bytesizebio.net […]